SMC 資料庫
聰明省電的人工智慧
文/國立臺灣科技大學電子工程系特聘教授 阮聖彰、國立臺灣科技大學電子工程系碩士生 徐崇皓
背景:
近年來,人工智慧(Artificial Intelligence,AI)及其深度學習(Deep Learning)技術發展之快,大大超出人們的認知和預期,並且已在影像辨識、自然語言處理等特定領域展現令人驚豔的成效也驗證其商業價值,甚至開始營利。然而,使用深度學習技術的運算所需要的代價是相當高的,除了需要強大和足夠的硬體資源,在運算過程中造成的功率消耗也是非常可觀。例如,藉由創造新型模型結構以減少運算量,而不影響辨識準確度的MobileNet,或是以量化、壓縮數值大小來達到加速省電效果的其他方案。因此,在不降低既有成效下,盡可能降低功率消耗,並維持現有的辨識準確度來節省資源與能源的消耗,便是未來大家關心的議題。
何謂深度學習
深度學習原理是以多層的類神經網路(Neural Networks)為架構,如同計算一道複雜的函數式,將真實世界的資訊轉為數位資訊後,經過一系列運算變換,進而取得與理想相近的答案,藉此人們可以利用深度學習方法求解許多無法以人為轉化為公式化分析的問題,也在解決問題的過程中發現了深度學習方法的潛力及其重要性。
就像人的學習過程一樣,深度學習架構模仿人類學習的過程和方法,可分為模型訓練(Training)和模型推論(Inference)兩階段。圖(一)以監督式學習(Supervised learning)用於數字辨識為例:在訓練階段,當我們將準備好的「數字」資料集送入深度類神經網路[註1]做訓練時,在網路輸出的另一端,有一系列與輸入資料對應的標記(Label)與網路輸出的辨識結果進行比對。若結果不為「數字」,那麼其與正確結果的差異量將經過反向傳播(Backpropagation)回饋至神經網路去調校權重(Weight)及偏差(Bias)等數據來進行模型更新,接著再進行下一次判斷的流程;如此周而復始,最終將獲得訓練好的模型數據。而在推論階段,我們將使用訓練完的模型數據,針對訓練時未見過的資料,來測試訓練過的模型在面對未知的資料輸入時是否能輸出正確的判斷結果。
再以生活化的例子來比喻,「訓練」階段就如學生準備考題的方式,平時針對過往出現過的考題進行練習,並在與標準答案對照的過程中查漏補缺再學習。而「推論」階段就如學生上考場實際測驗,對於從未見過的題目,是否能夠沉著應對並回應正確的答案。
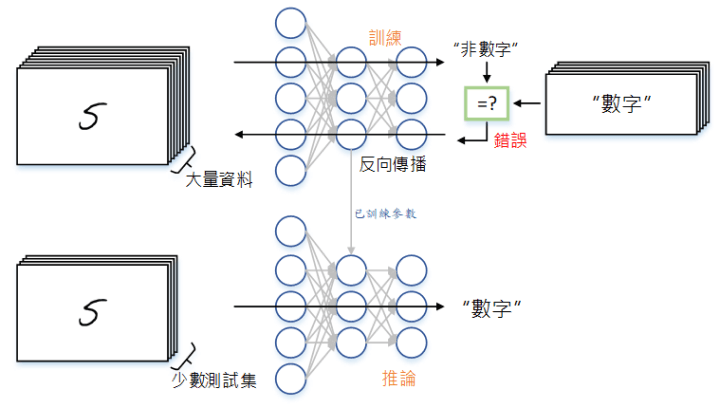
圖(一)深度學習的訓練與推論
深度學習與功耗的關聯性
然而,強大的深度類神經網路為了在推論階段得到更高的準確度,會傾向使用有高度資源存取需求且需要大量運算的深度學習模型。目前卷積神經網路(Convolution Neural Network,CNN)在此領域的進展突破佔有重要的地位,且為當前領域的發展主力。
CNN作為主流網路模型,其主要運算為大量的浮點數矩陣乘、加法,以圖(二)的示意圖為例,輸入的88 RGB 三通道(Channel)影像與第一個卷積層的卷積核(Convolution kernel)做卷積運算。所謂卷積運算,是將輸入影像中各通道33滑動視窗(Slide window)內的像素與33卷積核中相對位置的數值做乘積,並在最後加總起來得到卷積運算結果。重複此動作我們將獲得各通道影像與卷積核執行卷積運算後的結果,再將其相加總來得到卷積層輸出的特徵圖(Feature map),之後的卷積層也是如此的運算方式。如前所述,目前ResNet 等先進的CNN模型已經達到百層以上,運算量之大不難想像。例如在圖片識別應用上,微軟於2015年發表的深度殘差網路(Kaiming He et al,. 2015)[1],其152層的深度類神經網路,辨識錯誤率可低至3.5%。除了已能做到比人類的5%錯誤率還來得低的特點外,152層的深度也代表了網路深度對深度學習方法的影響和重要性。
當我們在評估一個模型或系統的性能時,往往看重其能耗。所謂的功耗(Power)就是功率的消耗;而能耗(Energy)則為能量實際的消耗。
E(能量) = P(功率) × T(時間)
從能量與功率的公式我們可以得知,能耗為功耗和時間的乘積。高功耗會引發高溫發熱的現象,而時間則是代表完成一項工作所需的時間,能耗代表的是性能。舉例來說,如果能在進行臉部辨識時,降低功率或是運算時間就能夠降低整體能耗(就如同車子一公升油可以跑多遠)。因此,在後PC時代,除了要顧及高功耗發熱高溫所帶來的昂貴冷卻費用,能源是更需要去關注的議題。
CNN大量的浮點矩陣乘加法運算,加上深度類神經網路的訓練階段需要大量的資料集,除了會佔用大量的儲存空間之外,還需要有更強大的硬體設備,例如能提供平行化加速的圖形處理器(Graphics Processing Unit,GPU)來做更有效率的運算,大量的數據存取以及運算雖然能讓準確度提升,但卻帶來了大量的功率消耗。正因為如此,許多有關降低運算資源需求、計算量及功率消耗的研究有如雨後春筍般出現,我們也應當重視此等問題並從中探尋改善之道。
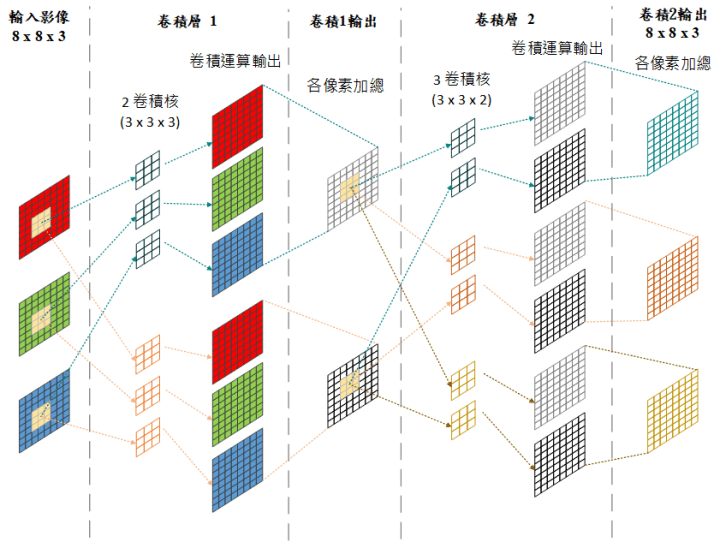
圖(二)卷積神經網路運算
解決深度學習功耗問題的方法
現今對於深度學習架構在精準度與運算時間優化的研究已經有了成熟的研究成果,但如何降低資源使用與功率消耗已慢慢變成研究的重點。目前有研究建議從減少儲存空間的使用和運算資源著手,且從理論發展到實作的過程有了很大的進展,這些應用甚至能在嵌入式系統如行動設備上進行模型推論實現,也稱為邊緣運算(Edge computing)。相關的方法基本上可以分成三種技術:量化(Quantization)、高效的模型設計、網路剪枝(Pruning)。量化是將32位元浮點數的模型權重轉化為較少位元數如16或8位元的形式,這樣一來存儲空間的占用量便會大大的減少,模型可至少壓縮一半以上的數據[註2]。由於降低了記憶體存取的次數,資源需求甚至能減少到只需從較快的內部SRAM(靜態隨機存取記憶體)存取,而非慢速的外部DRAM(動態隨機存取記憶體)[註3]。存取效率的提升以及整體處理時間的減少,使效能和能耗有了可觀的改善。
高效的模型設計如Google針對手機建構的MobileNet模型,其架構將卷積層劃分為深度卷積(Depthwise convolution)和點卷積(Pointwise convolution)兩部分,藉由更平行、細化的計算方式大幅降低了運算量,達到降低運算能耗的效果。例如與VGG-16網路模型相比,在相同準確率之下MobileNet模型的面積縮小了32倍、速度更是快了10倍。
網路剪枝則是在訓練階段時,藉由刪除不需要的類神經元連結來壓縮模型大小,因而能減少所需的硬體資源並且維持相當的學習能力,進而提升整體運算速度以及能耗的改善,近期的文獻指出已能達到十倍的可觀壓縮率[2]。
在深度學習架構中優化與效能的取捨
即便利用深度學習模型的壓縮和加速的方法能達到顯著的效能改善,但仍面臨許多挑戰,如前文所述的量化和網路剪枝為例,雖然透過這樣的方式個別降低了計算的資料量和模型的大小,卻可能難以在複雜的任務中達到預期的效果。甚至因為架構的調整,而對模型的穩定性產生影響,如何去調整其中的超參數(Hyperparameter)也變成了極端複雜的工作。此外在小型系統平台(如行動裝置、機器人、自動駕駛車)的硬體限制仍是阻礙深度學習發展的主要問題,比起壓縮,可能針對模型的加速更為重要。
嚴格來說,模型壓縮和加速其實是息息相關的,當模型經過壓縮後,運算的資源需求和存儲空間減少,使運算總時間下降,進而能達到加速的效果,但如果一味的追求模型的壓縮,最終帶來的卻可能是模型的不穩定或準確度的下降。若我們能在有限資源的環境,如小型系統平台或硬體上建構基礎的壓縮模型,並改以最大化利用現有資源的方式來提升運算的加速,更是一舉兩得甚至數得的絕佳方案。以改變運算方法來加速為例,從數學計算上乘加法轉為邏輯和位移運算就是一種很好的思路。
未來展望
由於人工智慧在各方應用的需求提升,除了在追求快速訓練和高準確度推論結果的架構外,針對低功率消耗和節省運算成本的研究,也是當前領域新的重要課題。而身在人工智慧風潮下的我們,也應當與時俱進,了解前人的成就與研究,發現更多新的領域和議題,開創智能、節能、利人的新未來。
註釋:
[註1] 人工神經網路(Artificial Neural Network,ANN),簡稱神經網路(Neural Network,NN)或類神經網路,此為翻譯上的差異,本文章提及「Deep Neural Network」的部分,以「深度類神經網路」稱呼。
[註2] 將32 Bits浮點數經過格式調整,改變以8 Bits定點數的形式來儲存,數值所占用的空間大小可變成原來的1/4。
[註3] 在電腦架構中,CPU的快取記憶體(Cache memory)由SRAM所構成,其速度雖可以接近處理器的頻率,但容量遠小於由DRAM構成的主記憶體。因此若資料不足以完全容納於快取記憶體,需要保存於主記憶體區塊的狀況下,存取所有資料時就需要更多的處理流程以及等待時間,進而會拖慢整個運算的週期,對效能和能耗的影響甚鉅。
參考文獻:
[1] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
[2] Han, S., Mao, H., & Dally, W. J. (2015). Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149.
版權聲明
本文歡迎媒體轉載使用,惟需附上資料來源,請註明新興科技媒體中心。
若有採訪需求或其他合作事宜,請聯絡媒體公關: