SMC 資料庫
「AI分析咳嗽聲可以辨別COVID-19無症狀感染者」之專家意見
議題背景
麻省理工學院(MIT)研究團隊開發了一個以卷積神經網路(CNN)為基礎的AI模型,運用人自願錄下的咳嗽聲資料庫訓練AI,再讓AI分辨出有COVID-19感染、無COVID-19感染,兩組人的咳嗽聲。研究團隊期望這個技術可以用非侵入性的方式,幫助更快速的預先篩檢可能的無症狀感染者。
此篇研究於2020年9月29日發表在〈IEEE醫學與生物工程雜誌期刊〉(IEEE Journal of Engineering in Medicine and Biology)。
- 研究原文:Laguarta, J., Hueto, F., & Subirana, B. (2020). “COVID-19 Artificial Intelligence Diagnosis using only Cough Recordings.” IEEE Open Journal of Engineering in Medicine and Biology.
- 錄下咳嗽聲給MIT:Record Your Cough, MIT website recording engine.
- 新聞報導:
- Knowing新聞〈新冠檢測新方法:MIT用咳嗽聲診斷無症狀感染者,準確率達100%!〉
- 科技報橘〈【揪出 COVID-19 無症狀患者!】麻省理工「AI 咳嗽聲模型」,從聲帶與呼吸反應做檢測〉
- Jennifer Chu(2020).“Artificial intelligence model detects asymptomatic Covid-19 infections through cellphone-recorded coughs.” MIT News Office, October 29. Retrieval Date: 2020/11/05
但是,目前AI可以用咳嗽聲「診斷」COVID-19感染嗎?這樣的技術有何特別,咳嗽聲性質、受測者的其他生理資料等會如何影響判斷結果?我們邀請專家釋疑。
專家怎麼說?
2020年11月17日
元智大學電機工程學系教授 方士豪
咳嗽聲是日常生活常見的聲學訊號。目前我們團隊已研究出許多AI技術,可透過典型的機器學習方法與人工標註的資料,從病患一秒的母音發聲偵測出聲帶疾病[1][2][3][4]。但若要診斷疾病,通常還需要搭配病患的其他基本資料,例如病史、性別、年齡、生活習慣等。
雖然說話聲與咳嗽聲都是輸入給AI學習的資料,但是這些資料的標記方式或應用可能不同。辨識說話的語音主要是讓AI能夠判斷出文字,而辨識咳嗽聲的目標是讓AI診斷疾病,兩者困難點不太相同,但使用的技術本質上接近。
目前新冠肺炎對肺的影響較大,肺的健康狀況又會連帶影響咳嗽聲,因此或許COVID-19肺炎與咳嗽聲的聲紋有正相關,但以此線索要「診斷」COVID-19感染,難度極高。此研究採用典型的機器學習技術區隔出COVID-19肺炎的咳嗽聲。因此限制在於資料蒐集時較難有一致性,比如說咳嗽的模式、使用的硬體,以及錄音的環境等。受測者的生理資料當然也會有差異,但通常個體差異不太能控制。另外就是資料的雜訊及標記問題。咳嗽聲音從肺開始一直到喉嚨發音結束,中間會經過一連串不同的通道,對聲音造成影響,因此通常會聽單純的肺音[5]而不是咳嗽聲,對於肺炎的診斷會較為直觀,也較少雜訊干擾。
在一般的AI應用中,比較常見的效能指標是準確度(accuracy)。但若為特殊的醫療應用,常見的效能指標是「敏感度」(sensitivity)和「特異度」(specificity)數值。比較通俗一點的說法是,不同的錯誤造成的代價不一樣。當生病的人被誤判成健康時,對個人健康的代價很高,因此會希望敏感度可以越高越好,可能偵測出越多感染者;另一方面,若是健康的人被誤判成生病,會造成醫療資源的浪費,因此希望特異度能越高越好,越不會誤判。多數的AI應用系統需考慮這兩個數值間的取捨。
此研究最後的效能達到98.5% 敏感度以及94.2% 特異度,效果好的驚人,幾乎可堪比市售檢測工具。但此研究是使用開放性的數據做訓練AI的資料,MIT提供免費錄音網站開放讓大家自己提供咳嗽聲,過程與標記未受到監督。在這樣的模式下,很有可能蒐集到健康人的假咳。要分辨健康人假咳與肺炎患者的咳嗽聲,對AI來說相對簡單,分辨的效果當然比較好,但比較困難的是分辨COVID-19肺炎病患和其他肺炎病患的咳嗽聲。因此項研究的臨床應用價值還需要更多更嚴謹的科學證據。
相關利益聲明:無相關利益
2020年11月10日
林口長庚紀念醫院檢驗醫學部講師級主治醫師 王信堯
敏感度跟特異度是臨床檢驗時,評估檢驗工具用在特定族群的效能指標。因此,須要先釐清該檢驗工具是用在COVID-19篩檢、確診或是後續追蹤的哪個階段,以及診斷時間點距離感染後與症狀出現後多久。唯有將這些臨床細節搞清楚,才有辦法知道一個檢驗的面貌,才有辦法適當的使用它而避免不切實際的期待。
越高的準確度不一定代表越好的檢驗。在疾病盛行率[6]與發生率[7]較低的區域,即便是敏感度很差的檢驗,仍會有很好的準確度。例如:在COVID-19盛行率只有1/1,000的區域,以一個「只會顯示陰性結果」的工具檢驗1,000個案例,則其準確度仍有999/1,000 = 99.9%,但是敏感度會是0,無法判斷出陽性的個體。因此在檢驗醫療領域常不注重準確度此指標,因為誤導的可能性很高。
咳嗽聲是因急速的吐氣動作,震動軟組織而產生。因此,不同族群或個體先天生理結構的差異,包括聲帶、鼻腔、咽喉、氣管等軟組織,以及有無抽煙造成軟組織纖維化等後天因素,都有可能造成不同的咳嗽聲。這些非常細微的差異,可能專業臨床醫師不一定聽得出來,但深度學習可藉由強大的識別能力而分辨其中的差異;然而,就是因為如此高的敏感度,可能造成其「過度擬合」的現象[8],而無法真正應用於真實世界。
基本上,臨床診斷很難分辨COVID-19病患和其他肺炎病患的咳嗽聲。也許可以用聽診分辨COVID-19跟細菌性肺炎,但即便用聽診也不太可能分辨COVID-19跟其他病毒性肺炎的呼吸音。
此篇研究在分析無症狀感染者較為精準的可能原因,我推測是因為研究蒐集到的COVID-19無症狀感染者,彼此的差異性較小,有集中趨勢,易於機器辨識學習;而有症狀的感染者,則類似其他病原感染的症狀,且各個軟組織受損與發炎的程度不同,造成統計上的異質性較大,無法輕易分析有症狀的感染者之間彼此的差異。
此篇研究使用咳嗽聲判斷無症狀感染者的敏感度能達到100%,但特異度只有83.2%,顯示AI無法有效分辨無症狀感染者和其他肺炎病患的咳嗽聲。不同病毒引起的肺炎,造成呼吸系統中軟組織的破壞基本上相似;加上咳嗽聲不是代表軟組織破壞的最直接指標[9],而是經由氣體震動受損組織後所產生。因此,在AI解析咳嗽聲的資料上可能就有它的侷限,難以分辨不同病毒造成的破壞。
相關利益聲明:無相關利益
2020年11月13日
飛利浦北美研究實驗室/麻省理工學院運算生理實驗室研究員 呂旻諭
臨床上,很多疾病都會引發咳嗽這種症狀,所以醫師很少單以咳嗽聲診斷疾病,必須搭配其他症狀、病史與篩檢結果,才會做出正確的診斷。而COVID-19的病人有70%都是無症狀,僅有30%的病人會有發燒、乾咳等症狀,目前診斷COVID-19的標準檢驗方法,是透過RT-PCR檢測鼻咽、喉嚨、血液或糞便的樣本。[10]
雖然這篇論文的結論相當新穎,然而訓練的模型若要能應用在臨床診斷,仍需要克服許多問題,第一個問題是資料集[11]。我們無從得知研究者如何搜集以及處理這些資料,也無法得知資料集是否只針對某一個特定地區、時間、或族群,以及依據什麼標準選擇陽性與陰性的樣本;是否有搜集其他疾病的咳嗽聲來訓練模型。另一個問題在於所有的標註資料都是患者自己在網站上填寫的,並不是由專業的醫療人員診斷及填寫,從該研究文獻中的Table1可以得知「自行評估」的資料佔了一半以上(58.9%)而「醫師評估」與「官方檢驗」的資料分別只佔了27.9%、13.1%[11]。也就是說,我們無從得知研究團隊收集的咳嗽聲,是否真的來自確診COVID-19的病人,所以很難去評斷這個檢驗模型是不是真的優於現在的RT-PCR檢測方法。
論文中只提供敏感度以及特異度的數值作參考,但敏感度代表的僅是,整個群體中有多少陽性個案被檢測出;特異度則代表,有多少陰性個案被檢測出。簡言之,如果一個模型預測所有人是陽性,則敏感度會是100%,特異度就會是0%。
準確度代表的則是預測正確的百分比,但如果用來測試模型的資料裡,陽性跟陰性的樣本數非常不平均, 那麼準確度也不能用來說明模型診斷的能力。舉例來說,如果一個群體裡有998個陽性和2個陰性,若用一個只能正確預測陽性的模型,那麼準確度就會是998除以1000=99.8%,但是特異度就會是0,表示無法判斷出陰性的個體。因此,醫學期刊論文常常需要附上偽陽性、偽陰性以及95%信賴區間(95% CI)的數據,才能夠對實驗結果有更全面的判斷。根據現有文獻,目前COVID-19的診斷工具,RT-PCR的敏感度僅在71-98%之間[12]。
此外,此篇研究者宣稱檢測無症狀的病人,模型可以達100%的準確度,但對於任何達到100% 效能的模型,我們建議大眾必須要抱持懷疑的態度。因為最常見的情況是「數據洩漏」(data leakage)或「標籤洩漏」(label leakage),意即在訓練模型的過程中,無意間把和結果相關的一些特徵也當作輸入給AI學習的資料。例如:COVID-19病人因為都在醫院錄音、COVID-19無症狀病人都被隔離在同樣環境、病人為了配合檢測而出現一致的咳嗽的方式等,模型可能無意間把這些病人的一致性當成重要的判別依據,並不是真的學到COVID-19造成的咳嗽聲特徵。
這篇論文提供了許多值得思考的面向及新穎的應用,例如利用咳嗽聲產生的生物標記作為訓練神經網路模型的資料特徵。但若能逐一解決上述問題,得到的模型會更有臨床參考的價值。有了之前《新英格蘭醫學期刊》(NEJM)與 《刺胳針》(Lancet)兩大期刊,撤銷COVID-19論文的前車之鑑[13],在釐清數據的品質與來源之前,我們需要更加謹慎的判斷研究結果。
相關利益聲明:無相關利益
2020年11月16日
基隆長庚醫院急診醫學科主治醫師/長庚大學臨床資訊與醫學統計研究中心副教授 陳冠甫
Taiwan AI Labs兼職工程師/林口長庚見習醫師長庚大學醫學系醫放所鄭仕群
林口長庚醫院急診醫學部住院醫師 許准銓
林口長庚醫院急診醫學部住院醫師 毛志揚
臨床上,醫師常用聽診器聽病患的呼吸音,以判別病人是否可能罹患肺炎。肺炎患者的呼吸音多呈現爆裂音,代表有肺部發炎、原本空洞的肺泡組織實質化等變化。然而醫師使用的是聽診器,而不是咳嗽聲音,在臨床上難以直接用咳嗽音來分辨病人是否有肺炎的可能。
臨床研究設計對結果的影響
針對「診斷工具」或是「預測模型」的相關研究,如何選取研究族群是影響可信度的重要因素。該研究使用「個案對照研究設計(case-control study)」,比較取樣族群光譜的兩極的白色區塊,為新冠肺炎患者和健康者(圖一),得到的模型表現是很好的,但這是常見的光譜偏誤[14]。當實際運用在光譜之中難以區分的病人族群(圖一的紅色區塊),診斷工具或是預測模型的效果就不如個案對照研究。許多報告研究結果的指引中[15],甚至建議避免使用個案對照研究的結果來給臨床照護人員指示。因此,由個案對照研究發展出來的模型,需要進一步以世代研究(cohort study)或橫斷型研究(cross-sectional study)驗證,所得到的模型表現才能被廣泛接受。
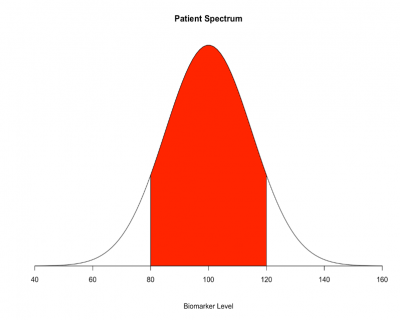
檢驗工具的優劣是以敏感度跟特異度評估:敏感度為一群有生病的人中,利用該檢驗工具確認生病的比例;特異度為一群健康的人中,利用該檢驗工具確認健康的比例。一個完美的試驗(黃金標準,Gold standard),即為100%生病的人都被檢測出生病,100%健康的人都被檢測為健康。敏感度跟特異度往往是互斥的,一個檢驗越敏感(幾乎每個有病的人都檢驗出有病),通常特異度就會不夠高(有些明明沒病,卻也被檢驗為有病)。而該研究使用的黃金標準,是任何人至該單位網站自我提報的結果,包含官方測試(Official tests)、醫師診斷以及自我評估。除了惡意或錯誤填報的可能性,此評估方式容易受到驗證偏誤[16],而高估敏感度和特異度。
AI模型的討論
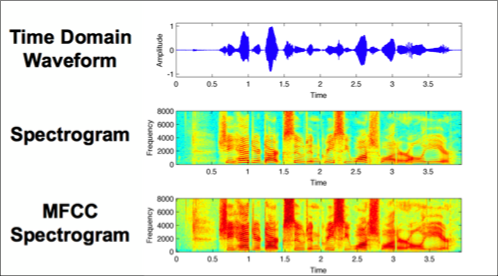
該研究先將聲音檔轉成MFCC光譜圖像(圖二下),再用卷積神經網路模型做深度學習,是常見的手法。MFCC光譜圖像相較於原本的時間區域波型(圖二上)和光譜圖像(圖二中)有更多細節,也更適合用卷積神經網路做深度學習。另外應用其他阿玆海默症研究ResNet50的參數,作為生物標記(Biomarker)參照。
然而,此論文並無實證其AI模型中各項生物標記是否對應他們賦予的疾病生理意義,也無佐證由阿玆海默症研究取得的生物標記與新冠肺炎有否顯著關聯,閱讀時應考慮其論述之嚴謹性。比較嚴謹的做法應是先篩選出與新冠肺炎病人咳嗽音顯著相關的因子,再於AI模型上實測出最佳效果的因子組合。此外,無法比較研究者提出之設計與其他標竿級模型之效果差異,只能得知在同樣的框架下,參數有預訓練過會比隨機起始好,而這早已是主流做法。至於可比較之標竿級模型,今年9月由Google Brain發表的Performer模型相當值得一試,其立基的注意力機制,已多次證實其效果或運算成本優於遞歸神經網路、卷積神經網路模型[17]。另外值得懷疑的是,高準確度(Area under the ROC Curve, AUC)恐怕是過度擬合所致,因該研究除了訓練資料集及驗證資料集外,並沒有設計測試資料集的使用;而在高度使用驗證資料集以取得最佳超參數(hyperparameters)的情況之下,多次使用驗證資料集必定造成過度擬合,在日後其他的資料集必定會產生較差的表現。最後,該研究輸入之MFCC二維數據尺寸只有300x200,尚不及主流ImageNet的平均值(482x418),而AI模型參數量至少就有三倍ResNet50預訓練模型,恐怕需要足夠的外部數據集測試才可證明該模型之泛用性。
全球在新冠肺炎的肆虐之下,科學家們無不卯足了勁來為全球人類找出篩檢新冠肺炎的好方法。然而,在方法學上,本次MIT的研究仍然有許多需要驗證的問題,需要臨床醫學研究人員進一步來解決,現在仍不適合直接用AI判讀咳嗽音的方式來篩檢新冠病毒。
相關利益聲明:無相關利益
2020年11月26日
國立中央大學生醫科學與工程學系副教授 黃輝揚
MIT的研究學者,透過網路上收集自願者用手機錄下咳嗽聲音,將聲音檔透過語音處理技術轉成梅爾頻率倒頻譜係數(MFCC)[18]的2D影像,透過深度學習訓練卷積神經網路(CNN),能夠偵測新冠肺炎病毒感染,在有正式檢驗報告的參與者中所得到的結果,靈敏度98.5%(有新冠病毒感染而被正確測出陽性的比率),特異性94.2%(無新冠病毒感染而被正確測為陰性的比率);在有正式檢驗報告而無症狀的參與者所得到的結果,靈敏度100%,特異性83.2%。這種優異的結果,在2020年11月初,受到網路上各大媒體的報導。在這個研究報告之前,美國俄克拉荷馬大學的學者在2020年6月有類似的研究報告[19],英國的劍橋大學目前也有類似的研究正在進行當中[20]。
面對這樣的好消息,尤其是診斷無症狀新冠病毒感染者的靈敏度達100%,我常聽到的反應是,這個新技術可以適用一般無症狀的大眾,做為普篩的利器對抗新冠肺炎。為了防止大家過於樂觀的反應,我要提醒大家的是另外一個數字,疾病感染率(infection rate)。根據BBC的報導[21],英國國家統計所(Office for National Statistics)的估計,目前在英格蘭每80人有一人感染新冠,在蘇格蘭每155人有一人感染,在威爾斯每165人有一人感染,在北愛爾蘭每135人有一人感染。如果在英格蘭做MIT咳嗽軟體測試,每80無症狀者會有1真陽性和13.4偽陽性(算法:80*(1-特異性83.2%)=13.4)。在蘇格蘭做MIT咳嗽軟體測試,每155無症狀者會有1真陽性和26偽陽性(算法:155*(1-特異性83.2%)=26)。所以,真、偽陽性的比例在英格蘭為1:13.4,在蘇格蘭為1:26,在威爾斯為1:27.7,在北愛爾蘭為1:22.7。
那在低感染率的台灣呢?我們假設每10,000人有一個人感染,在台灣做MIT咳嗽軟體測試,每10,000無症狀者會有1真陽性和1,680偽陽性。真、偽陽性的比例在台灣為1:1,680。
所以,這個軟體比較適用在有症狀者和感染發生率高的場所,如醫院。在高感染率的英格蘭做普篩也許還可做參考用,但在感染率極低的台灣,偽陽性的比例會太高,就不適合了。
註釋與參考資料:
[1] Shih-Hau Fang, Yu Taso., Min-Jing Hsiao, Ji-Ying Chen, Ying-Hui Lai, Feng-Chuan Lin, and Chi-Te Wang. (2019)“Detection of Pathological Voice Using Cepstrum Vectors: A Deep Learning Approach.”Journal of Voice, vol. 33, no.5, pp.634-641, Sep.
[2] Chi-Te Wang, Ying-Hui Lai, Sheng-Yang Tsui, Yu Tsao, Chii-Wann Lin, Feng-Chuan Lin, and Shih-Hau Fang. (2018)“Demographic and Symptomatic Features of Voice Disorders and Their Potential Application in Classification Using Machine Learning Algorithms”Folia Phoniatrica et Logopaedica, vol. 70, pp. 174-182, Sep.
[3] Shih-Hau Fang, Chi-Te Wang, Ji-Ying Chen, Yu Tsao, and Feng-Chuan Lin. (2019) “Combining Acoustic Signals and Medical Records to Improve Pathological Voice Classification”APSIPA Transactions on Signal and Information Processing, vol. 8 (E14), June.
[4] Yi-Te Hsu, Zining Zhu, Chi-Te Wang, Shih-Hau Fang, Frank Rudzicz and Yu Tsao. (2018)“Robustness against the channel effect in pathological voice detection”NeurIPS, Machine Learning for Health (ML4H) Workshop, Dec.
[5] 編註:空氣通過運動中的人體呼吸系統時,發出的聲音稱為肺音。
[6] 盛行率:指某一特定時間患有某一疾病的人口比例。
[7] 發生率:指某段時期內,新增某一疾病的人口比例。
[8] 「過度擬合」是目前機器學習(包含深度學習)模型所遇到的重大問題之一。「過度擬合」就是基於訓練資料的過度優化。簡單來說,就是模型針對考古題(訓練資料)過度優化,造成寫考古題成績很好,但卻無法在真實世界中有很好的分類/預測能力。
[9] 一個身體組織是否有破壞,解剖病理的切片檢查是最直接的證據。次之,我們可以用影像學檢查,如:電腦斷層、超音波、內視鏡等,來觀察組織是否有受到破壞。
[10] Hoang, Ansel, et al. (2020). “COVID-19 in 7780 pediatric patients: a systematic review.” EClinicalMedicine, 24: 100433.
[11] 編註:資料集在這篇中指的是用來訓練AI模型的所有資料,包含原始未被人工標註的資料、有人工標註的資料等。請參考MIT錄下咳嗽聲的網站〈Record Your Cough, MIT website recording engine.〉。
[12] Arevalo-Rodriguez, Ingrid, et al. (2020). “False-negative results of initial RT-PCR assays for COVID-19: a systematic review.” medRxiv.
[13] Andrew Joseph (2020). “Lancet, New England Journal retract Covid-19 studies, including one that raised safety concerns about malaria drugs” Stat News, June 4. Retrieval Date: 2020/11/13.
[14] 光譜偏誤(Spectrum bias):在生物統計學中,是指診斷測試的性能在不同的研究設計中因為不同的病人組合可能會有所不同的現象。
[15] Whiting, Penny F., et al. "QUADAS-2: a revised tool for the quality assessment of diagnostic accuracy studies." Annals of internal medicine 155.8 (2011): 529-536.
[16] 驗證偏誤(Verification bias):在統計學中,驗證偏差是一種測量偏差,其中診斷測試的結果會影響是否使用黃金標準程序來驗證測試結果,進一步造成對測試性能不公平驗證的表現。
[17] Dosovitskiy, Alexey, et al.(2020). "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale." arXivpreprint arXiv:2010.11929.
[18] 編註:梅爾頻率倒頻譜係數(Mel-Frequency Cepstral Coefficients),是一種讓電腦依據人的聽覺來處理語音訊號的方式,可以準確描述語音訊號的特徵。
[19] Imran, Ali, et al. (2020). “AI4COVID-19: AI enabled preliminary diagnosis for COVID-19 from cough samples via an app.”arXiv preprint arXiv:2004.01275
[20] 英國劍橋大學研究計畫請參考〈COVID-19 Sounds App〉。
[21] BBC News (2020).“Covid: Infection rates levelling off in England and Scotland.”Retrieval Date: 2020/12/01.
版權聲明
本文歡迎媒體轉載使用,惟需附上資料來源,請註明新興科技媒體中心。
若有採訪需求或其他合作事宜,請聯絡媒體公關: