SMC 資料庫
AI首度開發新抗生素之專家回應
議題背景:
今年2月底,臺灣各報紙媒體報導AI開發新抗生素的新聞,皆引用一篇發布在《細胞》(Cell)期刊的研究:A Deep Learning Approach to Antibiotic Discovery.
新聞指出,研究團隊訓練AI深度學習,首度在不預設任何前提的情況下,讓AI找出抑制細菌生長的分子。AI成功找到一個最低毒性、進入初步臨床研究的分子,由研究團隊命名為「halicin」,可以在實驗小鼠體內殺死四類具抗藥性的重大病原體。新聞提及AI可縮短新藥篩選時間、加速藥物開發,是全新的突破。
相關新聞:
- 蘋果日報:可消滅世上最危險細菌 美AI自行發現新抗生素
- 聯合報轉貼臺灣醒報:AI助攻醫學研發 發現最強抗生素
- 雅虎新聞轉貼匯流新聞網:「深度學習+人工智慧」技術發威 科學家靠他們找到可殺死超級抗藥性病菌
- 科技新報:MIT 學者利用 AI 發現超強抗生素,成果登《Cell》雜誌封面
然而,運用AI開發新藥物仍有許多必須考量的前提和挑戰。對此,專家分別給予回應如下:
專家怎麼說?
2020年3月9日
國立臺灣大學化學系 朱忠瀚助理教授
藥物分子之所以能成為抗生素,必須滿足兩個要件:(一)能夠抑制細菌生長、(二)對人體無害或毒性很低。該篇論文藉著AI深度學習的能力,從兩個複雜資料庫的數據中,嘗試找出分子結構與這兩個要件之間的關連,最後以實驗測試AI是否能精準地找出新的抗生素。
針對第一個要件,該文首先由研究團隊從美國食品藥物署(FDA)核准的2,560個藥物分子中,去除重複的225個後,以細菌實驗區分出「會抑制大腸桿菌生長」的120個分子與「沒有顯著抑菌效果」的2,215個分子,並將結果告訴AI,讓AI同時深度學習兩種資料,並且自行歸納出抑菌分子「該有什麼樣的結構」。接下來針對第二要件,該文作者使用了含有1,478個分子對人體毒性的資料庫,以同樣方法訓練AI深度學習,讓AI自行歸納出對人體無害的分子應有什麼樣的結構。雖然沒有預設AI用什麼方法歸納,但是必須預設「找有抑菌功能且對人體無毒性」此目標給AI。
以上的思維合情合理,但執行面卻有缺陷。首先,AI深度學習的成果,取決於訓練數據量的多寡。雖然尚未有研究明確顯示需要多少資料量才足夠,但是就如Google圖像辨識功能,動輒需要數百萬幅照片做訓練。該文作者僅採用2,560個分子資料庫中的2,335個分子,其實資料量相對較少。其次,抗菌機制大致可以分為五大類(破壞細胞膜、細胞壁,干擾核酸、蛋白質製造,或是阻止其他細菌代謝物的生合成),藥物分子結構也因抗菌機制的差異而不同。因此AI僅從120種已知「會抑制大腸桿菌生長」的分子,以及2,215個「抑菌效果不顯著」的分子中學習,恐怕很難歸納出針對抗菌機制的普遍適用規則。[註1] 如同透過寥寥幾個單字、例句來學習一個新的語言,多半只能學到一點皮毛。AI是否能從1,478個實驗數據中深度學習,針對藥物分子找出對人體毒性的規則,也不免令人有相同的疑慮。
最後,AI依據先前兩個步驟所學,在一億多個虛擬藥物分子中,先挑出它認為能抑制細菌生長的分子,再從中剔除它認為對人體有毒性的分子。經過這兩輪的篩選找出23個可能作為抗生素的分子。作者實際測試這23個分子的抑菌效果,結果僅8個有抑菌效果,其中6個效果不甚理想,僅有兩個分子抑菌效果顯著。其中一個分子雖然抑菌效果極佳,但結構卻與某些已知抗生素類似,實際上新發現的分子只有一個,這樣的效率只能算是低空飛過。
21世紀以來,傳統的藥物研發方法所找到的分子,僅有一種新的抗生素「Daptomycin」通過FDA審核上市[1]。[註2] 人類亟需新的方法來突破眼前的瓶頸,包含加速開發流程以及收集足夠的資料。該篇論文的結果雖然差強人意,但我認為這篇論文的重要性,在於它首次顯示出運用AI開發新抗生素的策略是可行的;如何取得大量、分子結構多樣性高且包含藥物交互作用資訊的資料來訓練AI,將會是日後AI抗生素研發能否繼續進步的關鍵。
2020年4月14日
中央研究院應用科學研究中心與生物醫學研究所合聘研究員/國立臺灣大學醫學院藥學系與長庚大學工學院合聘教授 林榮信
以此篇研究在新聞中的報導為例,針對AI開發新藥物的相關研究,分為四個層面說明:
- 訓練AI開發新抗生素或新藥,不是如新聞所說完全從零開始,而是需要預先假設或設定先決條件。這個預先的假設或是先決條件,就隱含在訓練AI模型的資料選取與處理中。目前運用AI開發新藥物的研究,花費大約80%的時間及心力,是在訓練AI之前,預先挑選並處理有問題和重複的資料。甚至若不同資料庫之間異質性較高,挑選及比對資料的過程需要更多時間,也必須先驗證訓練出的AI模型是否有效。這些都是研究時必須詳細設計的重點,也是判斷該篇研究可信程度的依據之一。若要報導這樣的研究,應該在新聞中簡明交待訓練AI所設定的資料條件和前提,會更幫助我們理解AI能開發新藥物的範圍及限制。
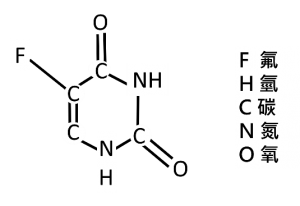
- 結構相似的分子因對不同疾病或生物體反應的效用不同,會影響針對特定疾病開發藥物時所訓練出的AI模型。本篇研究針對不同分子結構及化學相似性的概念為基礎,訓練AI深度學習開發新的抗生素。但分子結構的相似性並不是開發新藥物時可以完全倚賴的考量,有些相似的分子結構即使僅相差一個原子也可能造成藥物功能不同。例如抑制腫瘤細胞生長的藥物「5-氟尿嘧啶(Fluorouracil,5-FU)」,其化學結構式如[註3]所示。如果將此分子中唯一的氟原子換成氫或溴原子,它的藥物功用即消失[2]。這表示計算化學相似性的要求須非常精確,一個原子的差別都要能分辨出來。舉更極端的例子如藥物「氘(ㄉㄠ)代丁苯喹嗪(Deutetrabenazine)」,許多時候,即使將藥物分子中的氫換成原子序、電子分布結構都與氫相同的氘(ㄉㄠ),卻也會造成藥效的差異,此細微的改變可能產生另一種新藥,甚至還可以申請專利並得到FDA核准[3]。這些例子都是要讓大家知道,化學相似性這個概念在用AI演算藥物分子結構時的模糊性。簡單來說,化學相似性不能用絕對的數值大小來衡量,使用不同AI模型來計算,會有不同的化學相似性結果。另外,自然界實際存在的分子結構,可能會因為結合的蛋白質部位結構不同、溶液種類、酸鹼度,以及電解質強度等因素,和原來資料庫中紀錄的結構有差異,進入生物體試驗後也可能隨著所處細胞內環境及和其他分子的交互作用而變化。
- 運用AI開發藥物後,若要協助後續可於臨床實際使用,或許可以運用AI預測新藥物對生物體的副作用。的確有研究者在開發預測臨床試驗結果的方法,但是預測方式有很多樣態,要小心評估預測的結果與意涵。甚至,臨床前基於種種實驗結果與數據,依傳統方法判斷藥物應該無副作用,臨床使用卻不一定如此。更曾發生多起案例是藥物分子已經通過臨床試驗上市,卻在實際使用一段時間後才發現有副作用,著名的例子如美國默克藥廠(Merck)的關節炎藥物「偉克適錠(Vioxx)」。
- 雖然開發抗生素的過程耗時,程序漫長且藥廠利潤較低,但不應被新聞報導誤傳為過去所有藥廠都沒有成果。由於抗生素的範圍相當廣,也不應被誤解為只有與盤尼西林相關才屬於抗生素研究。此次也並非如新聞所述為人類首次完全利用AI來發現新抗生素,先前已陸續有相關運用AI協助抗生素研發的研究,例如新聞中受訪的評論者雅各布·杜蘭特(Jacob Durrant)就是這個領域的專家之一,可進一步閱讀其所著作的相關研究回顧[4]。
註釋:
[註1] 「能抑菌」的120筆資料和「不能抑菌」的2,215筆資料,對AI的深度學習同等重要。只要人類設定前提,AI總是可以歸納出「某些」規則,這些規則多有代表性、對人類理解抑菌機制有多大用處,則是另外一回事情。
[註2] 傳統的藥物研發方法是搜尋有抑菌功效的細菌發酵產物。Daptomycin即是由玫瑰孢鏈黴菌的發酵產物萃取而來,雖然在1987年已被跨國製藥公司禮來(Eli Lilly and Company)發現,但2003年才被美國FDA核准。
[註3] Fluorouracil結構式如圖:
版權聲明
本文歡迎媒體轉載使用,惟需附上資料來源,請註明新興科技媒體中心。
若有採訪需求或其他合作事宜,請聯絡媒體公關: